Que as inteligências artificiais se tornaram praticamente onipresentes, todos sabem. Não preciso dissertar muito sobre como os GPTs têm se infiltrado em nosso dia-a-dia, facilitando muito nossas vidas. Contudo, antes de nos aprofundarmos na questão do colapso de modelos das inteligências artificiais atuais, é necessário estabelecer dois pontos relevantes sobre as IAs:
O primeiro ponto é que uma inteligência artificial generativa não cria nada do zero. Ela é alimentada com terabytes de informações, os dados de treinamento. Uma IA generativa consegue trabalhar e reorganizar essas informações a partir de um diálogo (ou prompt) para te trazer a resposta que deseja. Esse tipo de rede neural que consegue trabalhar a escrita e a linguagem é chamado de LLM (Large Language Model, ou “grande modelo de linguagem” em tradução livre). Esses resultados que a IA retorna são os dados sintéticos — para distinguir de dados criados por humanos. A IA aparenta ter inteligência própria e poder criar algo, mas não tem. Ela gerou os dados sintéticos com base nos dados de treinamento já existentes.
Outro ponto importante: esses dados parecem perfeitos, mas não são. Os dados sintéticos gerados pelas IAs ainda contém inconsistências e imperfeições.
Um exemplo próprio, a vez que o ChatGPT resolveu o determinante de uma matriz transposta incorretamente. Eu, como físico, percebi o erro e informei o ChatGPT do erro (“mas o determinante de uma matriz transposta não é o mesmo determinante da matriz original?”). O ChatGPT prontamente “pediu desculpas” e, após três respostas diferentes umas das outras, finalmente me retornou o resultado correto. E aqui estamos falando de álgebra linear, um ramo da matemática, uma ciência exata. Imagine como uma IA lidaria com assuntos mais subjetivos como ciências sociais ou humanas.
Em outros casos, a IA pode retornar informações completamente distorcidas, das quais nem ao menos foram fornecidas pelos dados de treinamento originais. Na ciência da computação, chamamos essas respostas imaginárias de alucinações (sim, é esse o nome).
Como seria se os resultados da inteligência artificial fossem divulgados de forma indiscriminada por pessoas confiantes em seus resultados? Esses novos dados estarão disponíveis publicamente e, provavelmente, serão repetidos. Além de causar problemas com a propagação de informação falsa, essa é também a chave para o colapso de modelo das inteligências artificiais.
O que é colapso de modelo?

Imagine uma foto que alguém sobe na Internet. Essa imagem sofre uma leve degradação devido à compressão JPEG. Aí você salva essa imagem, e posta novamente. A imagem sofre mais compressão. Após subsequentes downloads e uploads, a imagem JPEG se torna extremamente degradada.
Os primeiros dados que alimentaram e treinaram as primeiras gerações das inteligências artificiais generativas foram criados por seres humanos: publicações, livros, artigos científicos, conhecimento publicamente disponível que foi criado, desenvolvido e selecionado por seres humanos. Por exemplo, o GitHub Copilot, uma IA que auxilia programadores no desenvolvimento de software, foi treinado com os dados disponíveis em repositórios públicos no próprio GitHub — código open source desenvolvido por programadores humanos experientes.
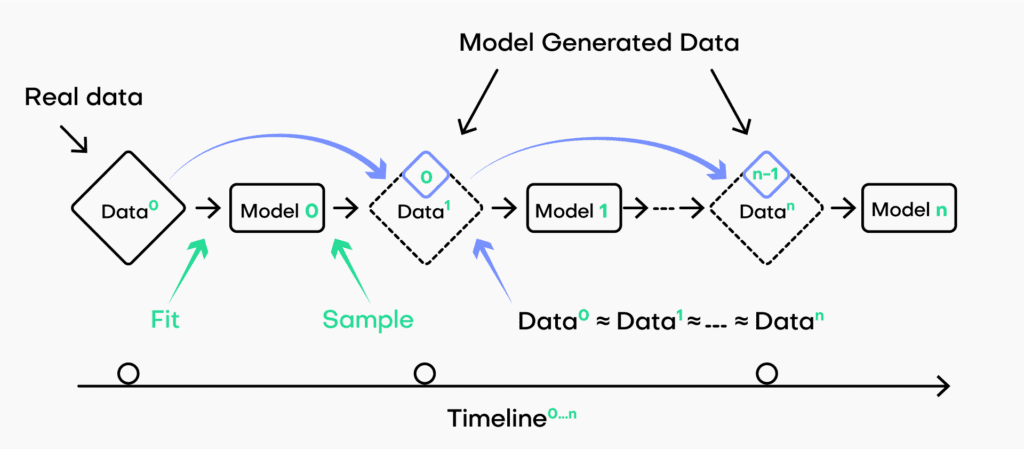
O colapso de modelo acontece quando os dados usados para treinar uma IA são dados sintéticos gerados por uma IA. A constante reprodução de conteúdo gerado por inteligência artificial faz com que aconteça um feedback: devido à incapacidade de distinguir dados reais dos dados gerados artificialmente, o conteúdo que passa a treinar os futuros modelos de IA são dados sintéticos gerados por modelos anteriores de IAs. Isso causa uma degradação nos dados, perda de precisão, inconsistências e erros. Os dados se tornam cada vez mais homogêneos, pois os dados que alimentam a IA foram gerados por uma IA, não mais dados raciocinados e desenvolvidos por seres humanos — lembre-se, uma IA não tem poder criativo. Os humanos trazem uma gama diversificada de pensamentos, sentimentos, experiências e perspectivas culturais, inclusive a intuição, que os dados sintéticos não conseguem replicar.
NOTA DO AUTOR: Para ter em mente como a intuição humana tem um forte papel no desenvolvimento científico, basta ver que a Teoria da Relatividade Geral foi desenvolvida a partir da intuição de Einstein de alguém dentro de um elevador em queda livre — o princípio da equivalência.
A expressão “lixo que entra é lixo que sai” é verdadeira quando falamos de IA.
- ChatGPT ficou ‘mais burro’ ao longo dos meses, afirmam pesquisadores de Stanford e Berkeley (Exame)
- ChatGPT está piorando e perdendo habilidades, diz estudo (Terra)
- Cansaço ou preguiça? Talvez o ChatGPT precise de férias (Olhar Digital)
- Desempenho do ChatGPT está piorando com o tempo, afirma um novo estudo (Cointelegraph Brasil)
Por que isso é relevante?
O colapso de modelo é importante porque a IA generativa está provocando mudanças significativas no conteúdo digital. Cada vez mais as comunicações online são geradas por meio de ferramentas de inteligência artificial, o que pode resultar em uma poluição de dados em grande escala. Embora a criação de grandes quantidades de texto seja mais eficiente do que nunca, o colapso de modelo afirma que nenhum destes dados será valioso para treinar a próxima geração de modelos de IA.
Mais poluição de dados gerada por IA torna os dados das interações humanas mais difíceis de encontrar (e mais valiosos). As empresas e plataformas com acesso a dados gerados por humanos terão maior probabilidade de criar modelos gerados por IA de alta qualidade. As empresas que conseguiram vasculhar a Internet antes da poluição da IA terão uma vantagem sobre aquelas que vasculharam a Internet pós-ChatGPT na busca de dados de treinamento de qualidade.

Um relatório publicado em 2023 analisando a relação entre a adoção do GitHub Copilot e a qualidade do código open source desenvolvido por programadores mostra que a qualidade de código diminuiu. A quantidade de linhas de código adicionadas e que, depois, foram removidas por erros de programação (chamado “churn”) aumentou desde a explosão da adoção das IAs como ferramentas de trabalho. Da mesma forma, a quantidade de código movido de lugar (processo chamado “refatoração”, que visa otimizar e aperfeiçoar o software) diminuiu. Esse é um trabalho ainda humano, pois IAs atuais ainda não conseguem trabalhar refatorações em larga escala. Isso é extremamente perigoso pelo fato de existirem softwares que colocam vidas humanas em risco, como os dos computadores de aviões — e devemos evitar tragédias causadas por erros de software, como o caso dos dois Boeing 737 MAX em 2018 e 2019.
NOTA: o relatório em PDF pode ser baixado aqui.


Em um artigo científico publicado também em 2023, os pesquisadores testaram três tipos de modelo de IA alimentando repetidamente dados gerados por modelos. Nos três casos, os pesquisadores encontraram casos de colapso de modelo:
- Modelo de misturas gaussianas (GMM): Um GMM foi projetado para separar dados em clusters usando uma distribuição gaussiana. Após 50 gerações, a distribuição de dados mudou completamente. Na geração 2000, não havia mais variação nos dados.
- Autocodificadores variacionais (VAE): O VAE foi treinado em dados reais e usado para gerar imagens de dígitos manuscritos. As próximas gerações foram treinadas com dados gerados pelo modelo. À medida que as gerações progrediam, as imagens ficaram progressivamente embaçadas até que cada dígito se parecia com uma mancha quase uniforme (imagem abaixo).
- Grande modelo de linguagem (LLM): O LLM (OPT-125m) foi ajustado usando apenas dados de modelos artificiais em um cenário e uma mistura de dados gerados pelo ser humano e dados artificiais em outro. Os pesquisadores descobriram que, embora o desempenho do modelo tenha degradado ao longo do tempo, algum nível de aprendizado era possível com dados gerados. Ainda assim, o exemplo dado no estudo mostrou várias saídas da OPT-125m respondendo a prompts sobre a arquitetura medieval, na qual, na quarta geração, o modelo estava gerando texto completamente irrelevante sobre lebres.

O colapso de modelo não é um problema apenas para desenvolvedores e pesquisadores de IA. É um problema para empresas, governos e qualquer pessoa que dependa da IA para agregar valor. À medida que dependemos cada vez mais da IA para agilizar as operações, tomar decisões informadas e fornecer serviços, o risco de colapso de modelo poderá ter implicações de longo prazo.
Os modelos de IA treinados em dados gerados por humanos podem refletir com mais precisão a diversidade e a complexidade dos cenários do mundo real. Isto não significa que devemos descartar totalmente os dados sintéticos, mas destaca a necessidade de manter um equilíbrio entre os dados sintéticos e os dados reais.